Những kiến thức nên biết về AI và LLM
Các nhánh của AI
AI là một mảng rất rộng nhưng không phải quá mới mẻ, mà đã xuất hiện từ những nằm 1950-1960. Nhận diện khuôn mặt trên ảnh, tự động lái xe, dự đoán thời tiết, tạo ra âm nhạc, và thậm chí chơi cờ vua/cờ vây - tất cả đều là các ứng dụng của AI.
AI có rất nhiều nhánh nhỏ và hơi khó phân loại:
- Machine Learning: Một phần của AI, nơi máy học từ dữ liệu và tự cải thiện qua thời gian.
- Computer Vision: Sử dụng Machine Learning để nhận diện và xử lý hình ảnh.
- Natural Language Processing (NLP): Sử dụng Machine Learning để hiểu, xử lý và tạo ra ngôn ngữ tự nhiên.
- Deep Learning: Một phần của Machine Learning, kết hợp với các mạng nơ-ron sâu để xử lý dữ liệu và ra quyết định.
- Generative AI: Tạo ra nội dung mới, như hình ảnh, văn bản, video, giọng nói âm nhạc.
Generative AI là một nhánh rất nhỏ của AI, nhưng có rất nhiều ứng dụng!
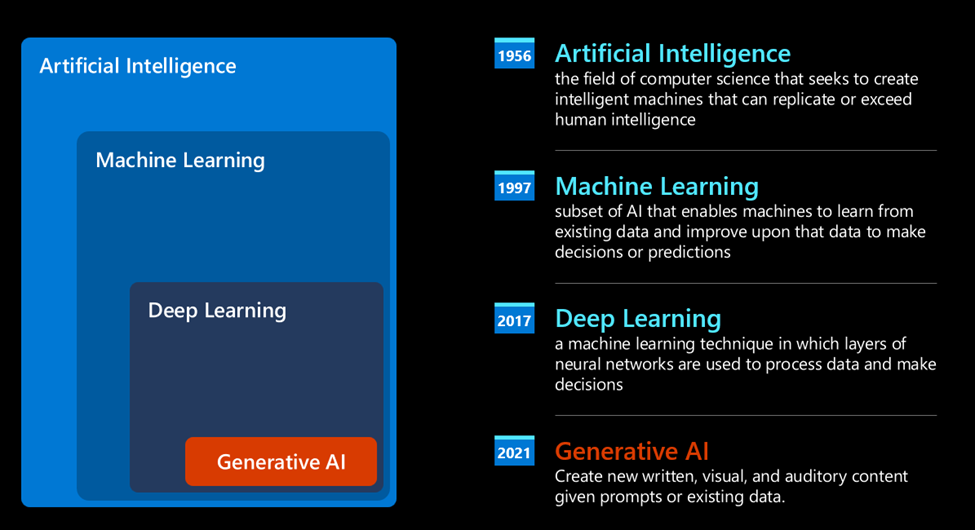
Trong toàn bộ các bài học của khoá học này, chúng ta sẽ tập trung vào Generative AI, một lĩnh vực đầy hứa hẹn và thú vị.
Supervised Learning và Unsupervised Learning - Nền tảng của LLM
Một phần lớn các ứng dụng của AI được dựa vào supervised learning, một phương pháp huấn luyện cho máy dự đoán/phân biệt bằng cách dựa vào các dữ liệu đã được gắn nhãn sắn.
Ví dụ, nếu bạn muốn máy học nhận diện mèo, bạn cần cung cấp cho nó nhiều hình ảnh mèo.
| Dữ liệu đầu vào | Nhãn |
|---|---|
| Ảnh mèo hoang | Mèo |
| Ảnh mèo tam thể | Mèo |
| Ảnh chó | Không phải Mèo |
| Ảnh gà | Không phải Mèo |
| Ảnh heo | Không phải Mèo |
Kết quả của phương pháp này sẽ là một model có khả năng dự đoán đúng nhãn cho các dữ liệu mới, hoặc đưa ra kết quả dựa trên dữ liệu đầu vào.

Supervised Learning còn có thể có nhiều ứng dụng khác:
| Dữ liệu đầu vào | Yêu cầu | Đầu ra |
|---|---|---|
| Nhận diện spam | Đánh giá email là spam hay không | |
| Hình ảnh | Đọc chữ (OCR) | Xác định nội dung văn bản trong ảnh |
| Hình ảnh | Nhận diện khuôn mặt | Xác định vị khuôn mặt trong ảnh |
| Văn bản | Phân loại chủ đề | Xác định chủ đề của văn bản |
| Dữ liệu y tế | Dự đoán bệnh | Dự đoán bệnh dựa trên triệu chứng |
Đây là một clip demo nổi tiếng về Convolutional Neural Networks (CNN), ứng dụng Supervised Learning để OCR, nhận diện số ở trong ảnh.
Một cách khác để huấn luyện cho máy là unsupervised learning, nơi máy học từ dữ liệu không gắn nhãn. Máy tự học từ dữ liệu mà không cần sự hướng dẫn của con người.
Ví dụ điển hình là clustering và dimensionality reduction. Đưa vào một số lượng lớn dữ liệu để máy tự phân loại, tìm hiểu các đặc điểm chung và gom nhóm, tạo dữ liệu mới.

LLM được huấn luyện như thế nào. Tại sao nó "thông minh"?
LLM - Viết tắt của Large Language Model - được huấn luyện và hoạt động dựa trên nguyên tắc tương tự:
- Ở giai đoạn đầu (pre-training), ta huấn luyện mô hình bằng cách cung cấp cho nó một lượng dữ liệu siêu lớn gồm các từ ngữ, câu văn, văn bản như sách, bài báo và trang web. Các mô hình hiện đại 2025-2026 như Llama 4 (Meta), DeepSeek V3 (671B tham số tổng, 37B active qua Mixture-of-Experts), Qwen 3.5 (Alibaba, 397B tham số) đều được học trên 15T+ token (tương đương hàng chục TB văn bản). Mô hình sẽ học từ dữ liệu này để hiểu ngôn ngữ tự nhiên và tự tìm ra quan hệ giữa các từ.
- Ở giai đoạn sau (fine-tuning hay SFT - Supervised Fine-Tuning), ta sẽ fine-tune mô hình với dữ liệu cụ thể, gắn nhãn những câu trả lời đúng với những câu hỏi để nó có thể trả lời câu hỏi một cách chính xác.
- Sau khi model đã có thể in ra câu trả lời có nghĩa, chúng ta còn áp dụng thêm Reinforcement Learning from Human Feedback (RLHF) và RLAIF (AI feedback), đánh giá những câu trả lời và chọn ra những câu trả lời đúng, hay và chính xác, để mô hình tự cải thiện dần qua thời gian.
- Các model mới 2025-2026 như
GPT-5,Claude Opus 4.7,Gemini 3 Procòn được huấn luyện thêm giai đoạn reasoning / chain-of-thought (CoT) để "suy nghĩ" trước khi trả lời, giúp giải quyết tốt các bài toán logic, code, toán học.
LLM hoạt động tương tự như chức năng autocomplete trên điện thoại của bạn. Khi bạn bắt đầu gõ một từ, điện thoại của bạn đề xuất các từ tiếp theo dựa trên ngữ cảnh.
| Dữ liệu đầu vào | Yêu cầu | Đầu ra (từ tiếp theo) |
|---|---|---|
| Nhà em có một | Đoán từ tiếp theo | con |
| Nhà em có một con | Đoán từ tiếp theo | chó |
| Nhà em có một con chó | Đoán từ tiếp theo | và |
| Nhà em có một con chó và | Đoán từ tiếp theo | nó |
Đi sâu về chi tiết thì nó phức tạp hơn nhiều, mình sẽ nói rõ thêm ở những bài sau dành cho các bạn học nâng cao nha.

Nhờ học từ lượng dữ liệu không lồ, LLM không chỉ ghi nhớ thông tin mà còn có thể tự học để tìm ra quy luật, quy nạp và diễn dịch thông tin dựa trên những kiến thức đầu vào.
Điều này cho phép chúng tạo ra văn bản mới, trả lời câu hỏi và thậm chí đưa ra suy luận dựa trên kiến thức chúng đã có.
Ví dụ, chắc chắn trong dữ liệu được học không có món thịt chó xào với sầu riêng, nhưng nếu bạn hỏi AI cách nấu món này, nó có thể đưa ra một câu trả lời hợp lý dựa trên kiến thức về cách nấu ăn (ăn được hay không lại là chuyện khác).

Vì vậy, khi bạn hỏi chatbot một câu hỏi, nó không chỉ đơn thuần đọc một câu trả lời đã được lập trình sẵn. Nó tạo ra câu trả lời một cách linh hoạt dựa trên kiến thức sâu rộng từ vài tỷ từ ngữ trong tập dữ liệu đầu vào, cùng với sự hiểu biết về ngôn ngữ của nó.
Tất nhiên, LLM không phải là vạn năng. Ở bài sau, bọn mình sẽ tìm hiểu về ưu/nhược điểm của nó, cũng như những khái niệm và các bạn nên biết nhé!
Tóm tắt bài học
- AI là một lĩnh vực rộng lớn, đã tồn tại từ những năm 1950-1960, với nhiều ứng dụng như nhận diện khuôn mặt, tự động lái xe, và dự đoán thời tiết.
- Các nhánh chính của AI bao gồm Machine Learning, Computer Vision, Natural Language Processing (NLP), Deep Learning, và Generative AI. Trong đó, Generative AI tập trung vào việc tạo ra nội dung mới.
- Supervised Learning và Unsupervised Learning là hai phương pháp huấn luyện chính cho AI. Supervised Learning sử dụng dữ liệu đã gắn nhãn để máy học và dự đoán, trong khi Unsupervised Learning cho phép máy tự học từ dữ liệu không gắn nhãn.
- Large Language Model (LLM) được huấn luyện từ một lượng lớn dữ liệu văn bản để hiểu ngôn ngữ tự nhiên và cải thiện khả năng trả lời thông qua fine-tuning và Reinforcement Learning.
- LLM hoạt động tương tự như chức năng autocomplete, cho phép tạo ra văn bản mới và đưa ra câu trả lời dựa trên kiến thức đã học từ hàng tỷ từ ngữ.
- Mặc dù LLM có khả năng tạo ra câu trả lời linh hoạt, nó không phải là hoàn hảo và sẽ được thảo luận thêm về ưu/nhược điểm trong các bài học sau.
Câu hỏi ôn tập
-
Tại sao Generative AI được coi là một nhánh nhỏ của AI nhưng lại có nhiều ứng dụng quan trọng?
Generative AI tuy là nhánh nhỏ nhưng có khả năng tạo ra nhiều loại nội dung đa dạng như văn bản, hình ảnh, video, âm nhạc. Điều này mở ra vô số ứng dụng trong nhiều lĩnh vực từ sáng tạo nội dung, thiết kế, giải trí đến giáo dục và nghiên cứu.
-
Sự khác biệt chính giữa Supervised Learning và Unsupervised Learning là gì?
Supervised Learning sử dụng dữ liệu đã được gắn nhãn để huấn luyện máy dự đoán/phân biệt (ví dụ: phân loại ảnh mèo), trong khi Unsupervised Learning cho phép máy tự học từ dữ liệu không gắn nhãn để tìm ra các mẫu và đặc điểm chung (ví dụ: clustering).
-
Tại sao LLM cần một lượng dữ liệu huấn luyện siêu lớn để hoạt động hiệu quả?
LLM cần lượng dữ liệu lớn (hàng tỷ từ ngữ) để có thể hiểu sâu về ngôn ngữ tự nhiên, nắm bắt được các mối quan hệ phức tạp giữa các từ, và phát triển khả năng suy luận. Các mô hình như Llama 4 của Meta sử dụng kiến trúc tiên tiến với hàng trăm tỷ tham số để đạt được hiệu quả cao.
-
Quá trình huấn luyện LLM gồm những giai đoạn nào?
Quá trình huấn luyện LLM gồm 3 giai đoạn chính: (1) Huấn luyện ban đầu với lượng dữ liệu siêu lớn, (2) Fine-tune với dữ liệu cụ thể có gắn nhãn, (3) Áp dụng Reinforcement Learning để cải thiện chất lượng câu trả lời qua thời gian.
-
Tại sao LLM có thể đưa ra câu trả lời cho những tình huống không có trong dữ liệu huấn luyện?
LLM không chỉ ghi nhớ thông tin mà còn có khả năng tự học để tìm ra quy luật, quy nạp và diễn dịch thông tin. Nhờ đó, nó có thể kết hợp các kiến thức đã học để tạo ra câu trả lời mới cho những tình huống chưa từng gặp, ví dụ như đưa ra công thức nấu ăn cho một món mới dựa trên hiểu biết về cách nấu nướng.