Embeddings - Biểu diễn số học của dữ liệu
Ở phần này, bọn mình sẽ cùng học về Embeddings và Vector Databases. Đây là 2 khái niệm nền tảng khá quan trọng trong việc xây dựng các ứng dụng sử dụng LLMs.
Embeddings là gì?
Ngôn ngữ là một thứ rất hay ho và... trừu tượng. Ví dụ như "trái cây" và "trái gió trở trời" đọc thì giống nhau, nhưng nghĩa lại khác nhau rất nhiều. Nhưng "trái cây" và "hoa quả", đọc thì khác, nhưng nghĩa lại giống nhau. Ta không thể chỉ dựa vào âm tiết, cách viết để hiểu được nghĩa của từ.
Vậy có cách nào để máy tính hiểu được nghĩa của từ? Hoặc hiểu được sự liên hệ giữa các từ, biết những từ nào nghĩa giống nhau, khác nhau hay không?
May thay là có, nếu ta biểu diễn chúng dưới dạng số học. Embeddings là biểu diễn số học của các văn bản, hình ảnh và âm thanh. Nói đơn giản, ta biến các từ/hình ảnh/âm thanh thành các vector số ([0.1, 034, 0.44]), dựa trên các đặc điểm, đặc tính và danh mục của chúng.
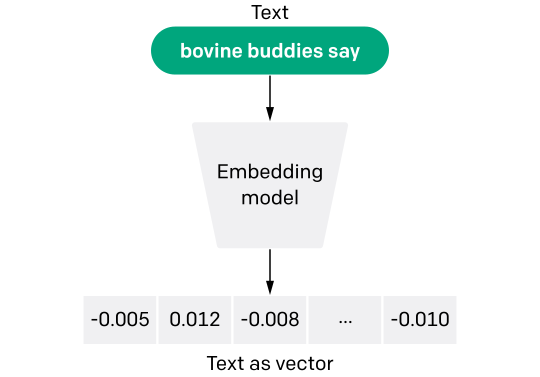
Sau khi chuyển thành vector, ta có thể sử dụng các phép toán vector để tính toán độ tương đồng giữa các vector, để hiểu được mức độ liên quan giữa các đối tượng.
Do vậy, embeddings giúp máy tính hiểu được sự tương đồng ngữ nghĩa giữa các đối tượng (2 từ này có liên quan hay không, 2 ảnh này có giống nhau hay không).
Tại sao embeddings lại quan trọng? Ứng dụng của nó?
Embeddings mang lại nhiều lợi ích quan trọng cho các mô hình deep learning và ứng dụng AI:
- Cải thiện khả năng hiểu dữ liệu thực tế: Giúp các mô hình deep learning xử lý các loại dữ liệu phức tạp một cách hiệu quả. Thay vì phải xử lý số, ảnh, chữ viết... giờ ta chỉ việc xử lý embeddings vector.
- Giảm chiều dữ liệu và giảm độ phức tạp: Embeddings đơn giản hóa việc biểu diễn dữ liệu nhiều chiều như văn bản, hình ảnh và âm thanh, giúp dễ dàng xử lý và phân tích hơn.
Trong thực tế, embeeding được ứng dụng như sau:
- Tìm kiếm (kết quả được xếp hạng theo độ liên quan với từ khóa tìm kiếm)
- Phân cụm (nhóm các văn bản có nội dung tương tự nhau)
- Gợi ý, đề xuất sản phẩm (đề xuất các mục có nội dung văn bản liên quan)
- Phát hiện bất thường (tìm ra các trường hợp lạ, ít liên quan với phần còn lại)
- Phân loại (phân loại văn bản dựa trên nhãn tương đồng nhất)
Ví dụ, khi các bạn tìm kiếm "áo khoác" trên Shopee hoặc Google. Thay vì tìm các sản phẩm có chứa từ "áo khoác", ta có thể dùng embedding để tìm các sản phẩm tên tương tự như "áo phông", "áo len", "áo gió",...
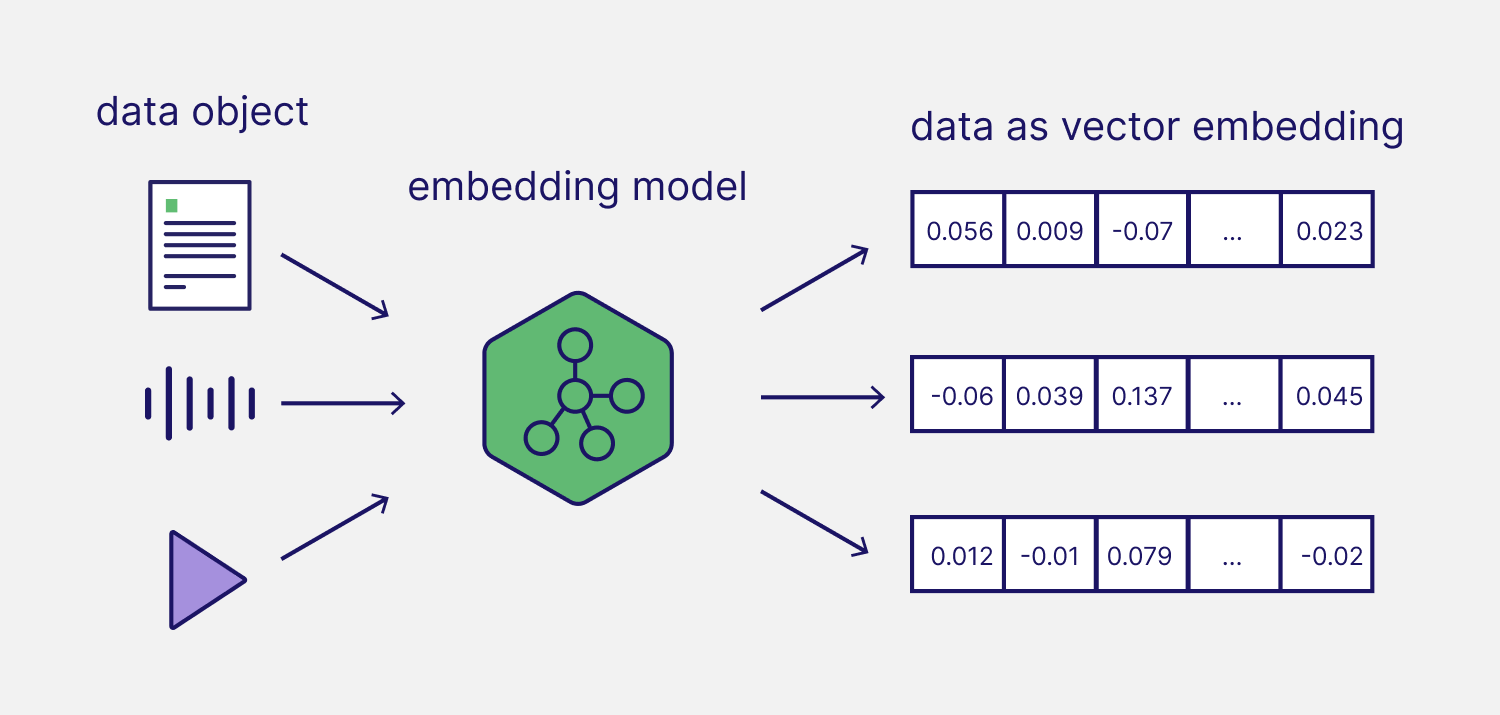
Embedding Models (Mô hình embedding)
Vậy làm sao để biến một từ hoặc một câu thành embedding? Ta sử dụng embedding models.
Một trong những embedding model phổ biến đầu tiên là word2vec
Thuật toán Word2vec sử dụng một neuron network để học các liên kết từ (sự liên quan của từ) từ một kho ngữ liệu văn bản có dung lượng lớn.
Sau khi được huấn luyện, mô hình có thể phát hiện các từ đồng nghĩa hoặc gợi ý các từ bổ sung cho một phần của câu.
Với cái tên nói lên tất cả, word2vec thể hiện cho mỗi từ riêng biệt với một danh sách cụ thể của các số được gọi là vector.
Về sau, có nhiều embeeding model mới hơn ra đời, BERT của Google là một trong số đó (Nghe nói bây giờ họ vẫn sử dụng BERT trong quá trình tìm kiếm).
Các mô hình embedding chủ yếu khác nhau về đầu vào tối đa + số chiều trong vector đầu ra. Các mô hình lớn hơn, nhiều chiều hơn có thể nắm bắt nhiều thông tin hơn, nhưng tốn nhiều tài nguyên tính toán hơn.
Trên thực tế, ta không cần tự train mô hình embedding, vì đã có rất nhiều mô hình sẵn có. Một số mô hình embedding phổ biến (2026) bao gồm:
- OpenAI:
text-embedding-3-small(rẻ, 1536 dim),text-embedding-3-large(mạnh nhất, 3072 dim) — https://platform.openai.com/docs/guides/embeddings - Google:
text-embedding-004,gemini-embedding-001(multilingual, hot model cuối 2025) - Cohere:
embed-v4.0— multimodal (text + image), hỗ trợ 100+ ngôn ngữ - Open-source (chạy local qua
sentence-transformers):BAAI/bge-m3— multilingual, hot nhất 2024-2026nomic-ai/nomic-embed-text-v2— mã nguồn mở đầy đủAlibaba-NLP/gte-multilingual-base— top tiếng Việtall-mpnet-base-v2,all-MiniLM-L12-v2— các model nhẹ, legacy nhưng vẫn ổn
Lời khuyên 2026: Nếu bạn làm sản phẩm thương mại, cân nhắc sử dụng
text-embedding-3-largehoặcgemini-embedding-001. Nếu muốn self-host,bge-m3hoặcgte-multilingual-baselà lựa chọn rất tốt cho tiếng Việt.
Ví dụ về cách tạo embedding
Ví dụ, mình có 1 từ đầu vào là "dog". Khi sử dụng model all-MiniLM-L12-v2, từ này sẽ được biểu diễn dưới dạng một vector với 384 chiều.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L12-v2')
embedding = model.encode("dog")
print(embedding)
Kết quả:
[ 3.48497152e-01 -3.84317964e-01 -1.15802266e-01 2.03050867e-01
-4.31225628e-01 -1.85827410e-03 7.11700320e-03 1.20060341e-02
...
7.13369623e-02 -2.01146543e-01 -6.64063990e-02 -6.98207021e-02]
Một embedding là một vector (danh sách) các số thực. Từ vector embedding này, ta có thể dùng các phép tính vector để tính toán khoảng cách giữa các vector.
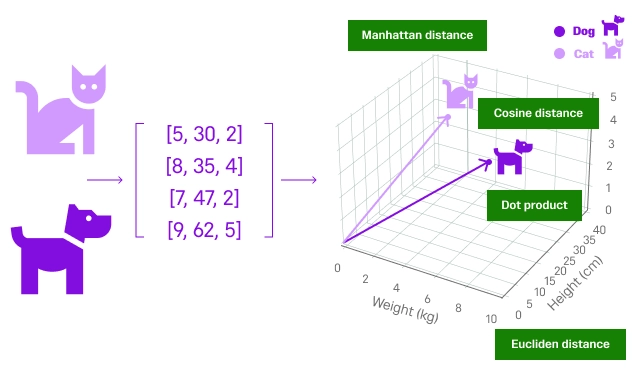
Từ đó, ta hiểu được mức độ liên quan giữa các từ, ảnh hoặc đoạn văn.
⭐ Source code (cho khoá Engineer): 02-embedding-vector-db/01-embedding.py
Ở bài sau, chúng ta sẽ tính toán độ tương đồng giữa các vector, để tìm các từ liên quan với từ đưa vào nhất.
Tạm kết
Ở bài này, chúng ta đã học về embeddings và cách tạo embedding (vector) với mô hình sẵn có.
Vậy các embedding này được lưu trữ ở đâu, sử dụng như thế nào?
Ở bài tiếp theo, chúng ta sẽ cùng học về Vector Databases, nơi lưu trữ các embeddings nhé.
Tài liệu tham khảo
Tóm tắt bài học
- Embeddings là biểu diễn số học của dữ liệu, giúp máy tính hiểu được sự tương đồng ngữ nghĩa giữa các từ, hình ảnh và âm thanh bằng cách chuyển đổi chúng thành các vector số.
- Việc sử dụng embeddings giúp cải thiện khả năng hiểu dữ liệu thực tế và giảm độ phức tạp trong xử lý thông tin, cho phép ứng dụng trong nhiều lĩnh vực như tìm kiếm, phân cụm, gợi ý sản phẩm, phát hiện bất thường, và phân loại.
- Các mô hình embedding như word2vec và BERT là những công cụ phổ biến để chuyển đổi từ hoặc câu thành embeddings, giúp phát hiện các từ đồng nghĩa và gợi ý từ bổ sung.
Câu hỏi ôn tập
-
Làm thế nào embedding có thể giúp máy tính hiểu được sự tương đồng về ngữ nghĩa giữa các từ khác nhau?
Embedding chuyển đổi từ ngữ thành các vector số học dựa trên đặc điểm và ngữ cảnh của chúng. Thông qua việc biểu diễn số học này, máy tính có thể sử dụng các phép toán vector để tính toán độ tương đồng giữa các từ. Ví dụ, các từ có nghĩa gần nhau như "trái cây" và "hoa quả" sẽ có vector biểu diễn gần nhau trong không gian vector.
-
Tại sao embedding lại đóng vai trò quan trọng trong các ứng dụng AI hiện đại?
Embedding giúp cải thiện khả năng hiểu dữ liệu thực tế của các mô hình deep learning bằng cách chuyển đổi dữ liệu phức tạp (văn bản, hình ảnh, âm thanh) thành dạng vector đơn giản. Điều này giúp giảm chiều dữ liệu, đơn giản hóa việc xử lý và được ứng dụng rộng rãi trong tìm kiếm, phân cụm, gợi ý sản phẩm và phát hiện bất thường.
-
Các mô hình embedding phổ biến hiện nay là gì và chúng khác nhau như thế nào?
Một số mô hình embedding phổ biến bao gồm
text-embedding-3-small/largecủa OpenAI,all-mpnet-base-v2củasentence-transformers. Các mô hình này chủ yếu khác nhau về kích thước đầu vào tối đa và số chiều trong vector đầu ra. Mô hình lớn hơn có thể nắm bắt nhiều thông tin hơn nhưng cũng tốn nhiều tài nguyên tính toán hơn. -
Làm thế nào để tạo embedding từ một từ hoặc câu văn bản?
Để tạo embedding, ta có thể sử dụng các mô hình embedding có sẵn như
sentence-transformers. Ví dụ, sử dụng modelall-MiniLM-L12-v2, ta có thể chuyển đổi một từ thành vector 384 chiều thông qua hàmencode(). Vector này sau đó có thể được sử dụng để tính toán độ tương đồng với các vector khác. -
Word2vec hoạt động như thế nào và tại sao nó lại là một bước đột phá trong lĩnh vực xử lý ngôn ngữ tự nhiên?
Word2vec là một thuật toán sử dụng mạng neural để học các liên kết từ từ kho ngữ liệu lớn. Nó là bước đột phá vì có khả năng phát hiện từ đồng nghĩa và gợi ý từ bổ sung cho câu. Word2vec biểu diễn mỗi từ bằng một vector số, tạo nền tảng cho việc phát triển các mô hình embedding hiện đại như BERT.