Cơ bản về RAG (Retrieval Augmented Generation) - Phần 1
Chào các bạn! Hôm nay mình sẽ cùng tìm hiểu về một công nghệ rất thú vị trong lĩnh vực AI - đó là Retrieval Augmented Generation (RAG).
Như mình đã nhắc lại nhiều lần ở các bài trước, GPT và các LLM khác cũng có một số hạn chế về mặt dữ liệu và kiến thức:
- Ví dụ như khi bạn hỏi về tin tức mới nhất, ChatGPT có thể không biết vì nó chỉ được huấn luyện với dữ liệu cũ.
- Hoặc khi các bạn cần truy vấn dữ liệu mật (dữ liệu của tổ chức, khách hàng, cá nhân...) thì LLM hoàn toàn mù tịt, vì nó có biết gì đâu mà trả lời!
Để giải quyết vấn đề này, người ta sử dụng một kĩ thuật được gọi là Retrieval Augmented Generation - RAG. Tạm dịch là Tạo nội dung (Generation) với sự trợ giúp (Augmented) của truy xuất (Retrieval) dữ liệu.
Cập nhật (2026-04): "RAG" ngày nay thường không chỉ là "vector search rồi nhét vào prompt". Hệ thống production hay có thêm các bước như: lọc theo metadata, hybrid search (keyword + vector), reranking (Cohere Rerank, BGE Reranker), trích dẫn nguồn (citations), prompt caching, và đánh giá chất lượng (RAG eval với Ragas, TruLens).
Ngoài ra, 2 hướng tiếp cận mới đang rất hot:
- Agentic RAG: Dùng AI agent (với function calling) để chủ động quyết định khi nào cần search, search cái gì, tổng hợp ra sao. Smartest hơn RAG cổ điển.
- Context-engineered RAG: Với các model context window cực lớn (GPT-5.4 400k, Claude 1M, Gemini 3.x 1M-2M, Llama 4 Scout 10M tokens), đôi khi nhồi thẳng document vào prompt + prompt caching lại hiệu quả hơn chunking + vector search.
Trong khoá này, chúng mình tập trung vào flow cốt lõi để bạn nắm nguyên lý trước, rồi sẽ bàn kĩ hơn trong phần Production.
Ví dụ đơn giản về RAG
Giả sử bạn muốn làm một con bot để tư vấn về các sản phẩm của công ty. Nhưng LLM thì làm sao biết công ty có những sản phẩm nào, giá cả ra sao để tư vấn?
Một cách đơn giản nhất là bạn có thể để toàn bộ thông tin sản phẩm vào prompt của LLM. Cách này chạy được, nhưng nếu danh mục tầm vài triệu sản phẩm thì không ổn.
Lúc này, ta có thể làm như sau:
- Khi người dùng có câu hỏi, ta sẽ truy xuất các sản phẩm liên quan từ cơ sở dữ liệu
- Sau đó, ta sẽ truyền các sản phẩm liên quan vào prompt của LLM
- Lúc này, LLM sẽ kết hợp các sản phẩm liên quan với câu hỏi của người dùng để tạo ra câu trả lời
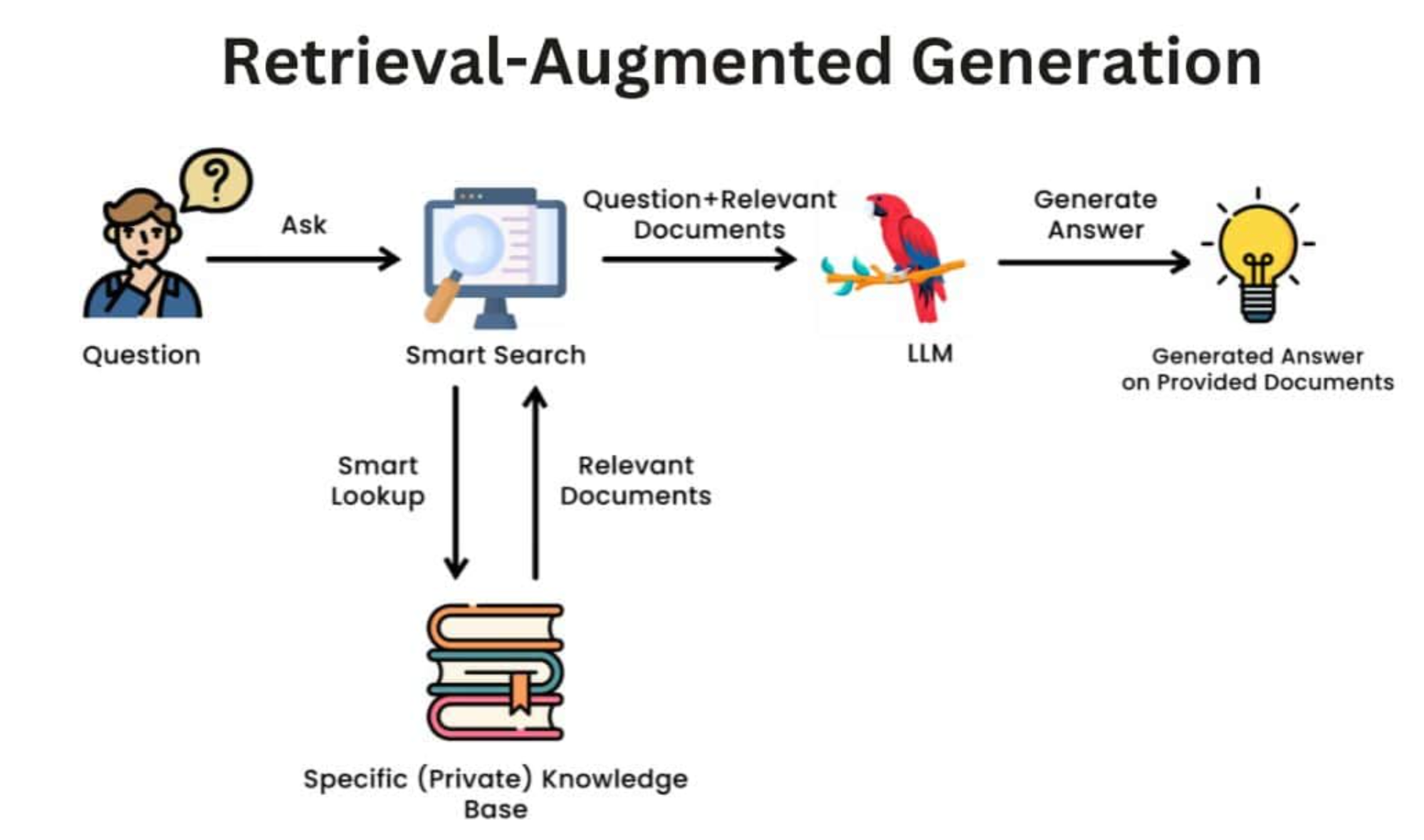
Đó, nghe thì phức tạp nhưng đây là nguyên tắc hoạt động cơ bản của RAG. Cũng không quá khó hiểu đúng không nào?
RAG là gì, nó hoạt động ra sao?
RAG (Retrieval Augmented Generation) là một kỹ thuật kết hợp giữa việc truy xuất thông tin (retrieval) và tạo nội dung (generation) để nâng cao chất lượng câu trả lời của LLM. Nó cho phép LLM truy cập thông tin từ các nguồn dữ liệu bên ngoài, thay vì chỉ dựa vào kiến thức đã được huấn luyện.
Về cơ bản, RAG hoạt động bằng cách tìm kiếm thông tin liên quan từ nguồn dữ liệu (như tài liệu, cơ sở dữ liệu) và đưa thông tin đó vào làm ngữ cảnh (context) cho LLM khi tạo câu trả lời. Điều này giúp LLM có thêm thông tin chính xác (kèm nguồn tham khảo) để trả lời tốt hơn.
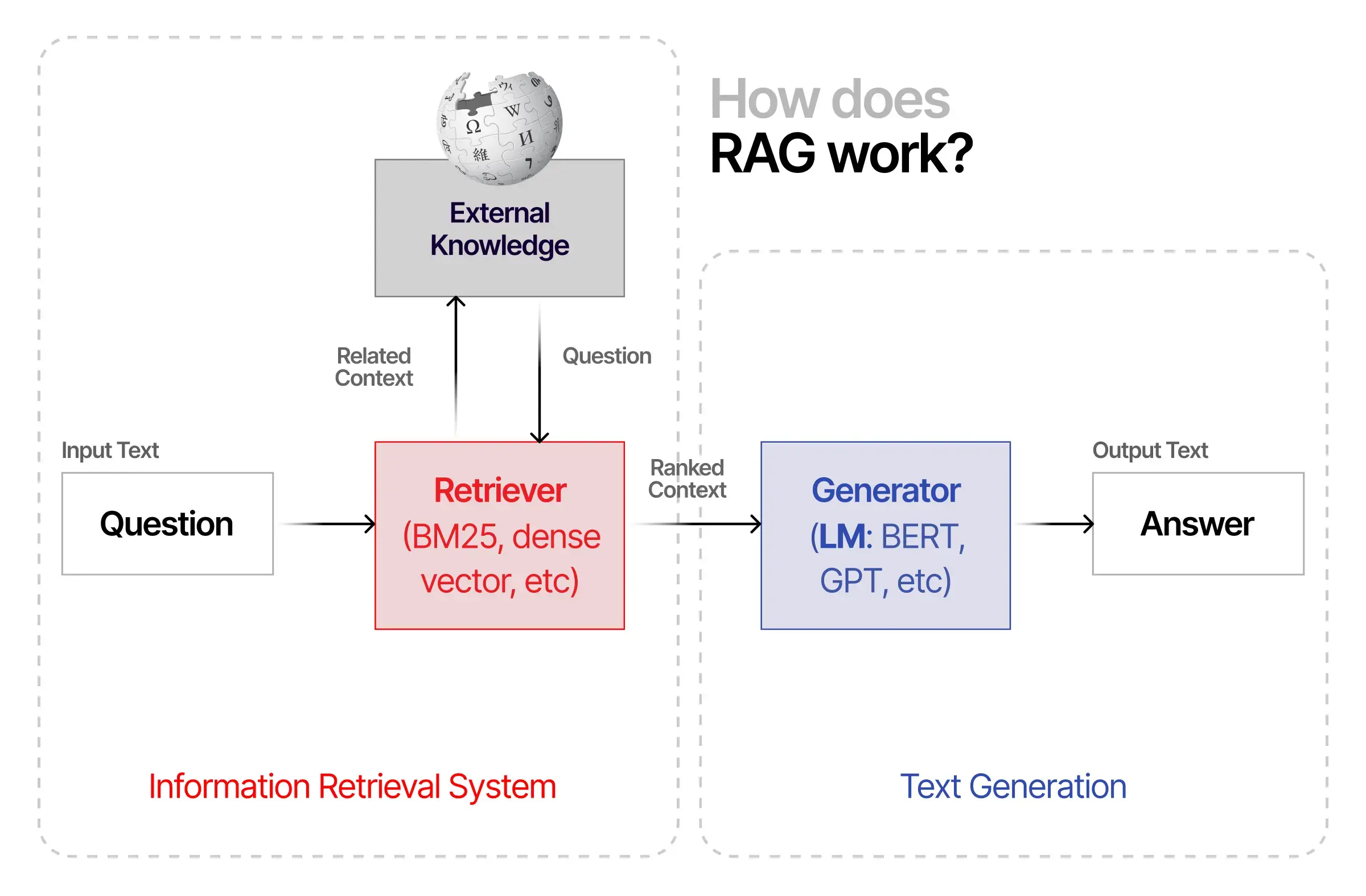
Các bước cơ bản của RAG
Trong 1 flow RAG cơ bản, chúng ta sẽ thực hiện các bước sau. Ba bước đầu tiên (0, 1, 2) dựa trên kĩ thuật embedding & vector database mà ta học ở bài trước.
-
Chuẩn bị dữ liệu: Chuyển đổi dữ liệu thô (văn bản, tài liệu) từ knowledge base thành các vector số (embeddings) và lưu trữ chúng vào vector database có thể tìm kiếm hiệu quả sau này. Bước này sẽ được làm 1 lần, cập nhật khi có dữ liệu mới.
-
Xử lý câu hỏi: Khi người dùng đặt câu hỏi, hệ thống sẽ chuyển đổi câu hỏi đó thành vector để chuẩn bị cho việc tìm kiếm.
-
Tìm kiếm thông tin liên quan: Hệ thống so sánh vector của câu hỏi với các vector trong cơ sở dữ liệu để tìm ra những thông tin có nội dung gần gũi, liên quan nhất. Những thông tin này sẽ được dùng làm ngữ cảnh cho LLM.
-
Tạo câu trả lời: LLM sẽ đọc câu hỏi của người dùng kết hợp với những thông tin liên quan vừa tìm được để tạo ra câu trả lời chính xác.
Tuy nhiên, bạn không nhất thiết phải sử dụng vector database ở bước 1-2, mà có thể lấy thông tin từ API bên ngoài, query từ Database của hệ thống theo keyword...
Ví dụ, bạn có thể gọi API của Google để lấy thông liên quan đến câu hỏi của người dùng, đưa nó vào context cho LLM trả lời.
Tại sao RAG lại quan trọng. Nó được dùng cho mục đích gì?
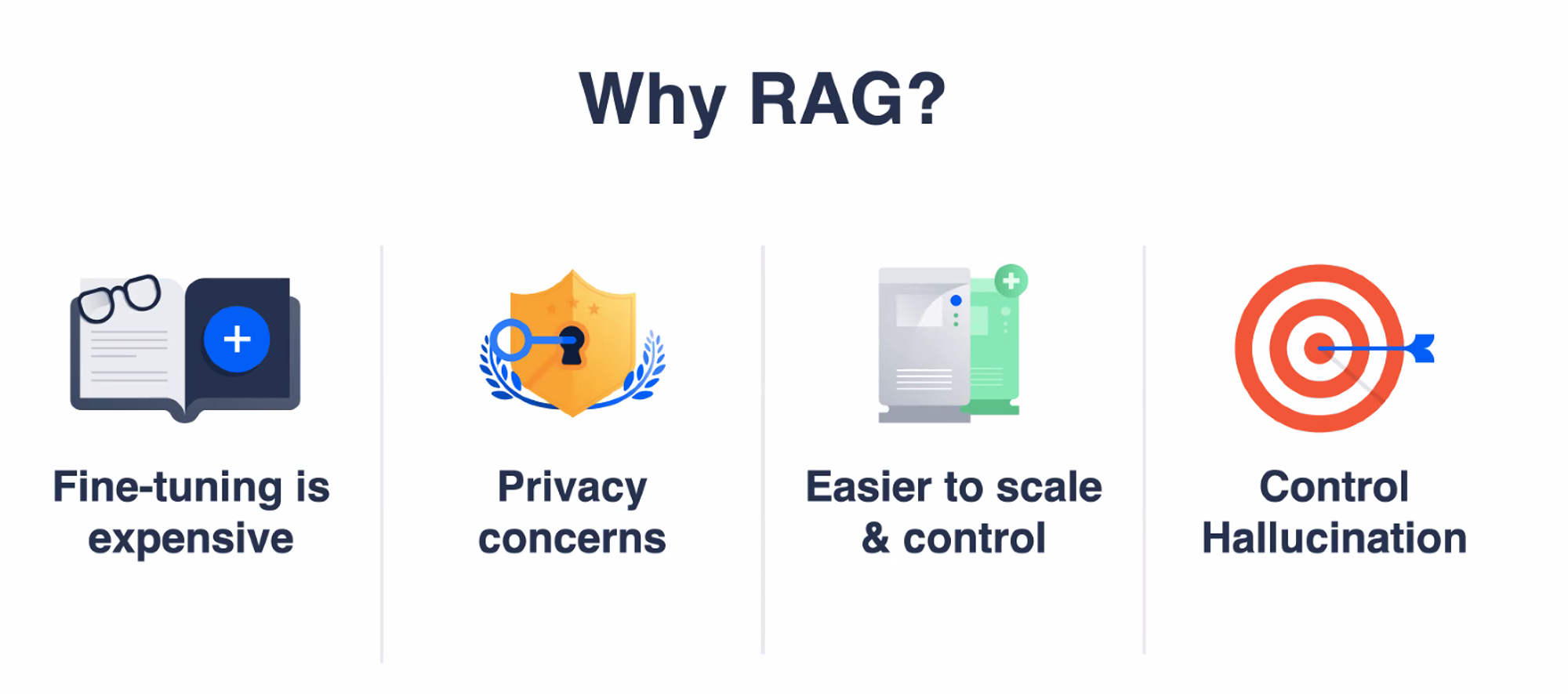
RAG ra đời để giải quyết một số vấn đề lớn của các mô hình ngôn ngữ lớn (LLMs):
- Cập nhật kiến thức: LLMs chỉ biết những gì được học trong quá trình huấn luyện. Với RAG, ta có thể cập nhật thông tin mới mà không cần huấn luyện lại mô hình.
- Độ chính xác: LLMs có thể "tưởng tượng" ra thông tin sai khi không có đủ ngữ cảnh. RAG giúp cung cấp thông tin chính xác từ nguồn đáng tin cậy. Nếu không tìm được thông tin, nó có thể bảo LLM trả lời "Không biết" thay vì tự chế.
- Minh bạch: Thay vì hoạt động như "hộp đen", RAG cho phép trích dẫn nguồn thông tin rõ ràng. Nhờ điều này, bạn có thể làm các tính năng rất hay như đưa link trích dẫn/tài liệu liên quan từ nguồn (như hình dưới)
- Tiết kiệm chi phí: Thay vì phải huấn luyện/tinh chỉnh lại mô hình cho từng use case (rất tốn kém), ta chỉ cần cập nhật nguồn dữ liệu cho RAG.
RAG giải quyết những vấn đề này bằng cách truy cập và tích hợp thông tin liên quan trong quá trình tạo trả lời. Điều này đảm bảo tính chính xác và minh bạch bằng cách trích dẫn nguồn, tương tự như các tài liệu tham khảo học thuật.
Do vậy, RAG được ứng dụng rộng rãi trong nhiều lĩnh vực như:
- Trả lời câu hỏi dựa trên tài liệu nội bộ
- Tóm tắt báo cáo, tài liệu tự động
- Xây dựng chatbot tư vấn khách hàng với thông tin sản phẩm cập nhật, chốt đơn
- Hỗ trợ tra cứu và phân tích tài liệu pháp lý
Kết luận
RAG là một công nghệ quan trọng trong tích hợp LLM vào các hệ thống sẵn có. Nó giúp LLMs truy cập thông tin từ nhiều nguồn khác nhau, đảm bảo câu trả lời chính xác và minh bạch.
Ở bài sau, bọn mình sẽ giới thiệu các RAG flow từ đơn giản tới phức tạp, và so sánh RAG với Function Calling nhé!
Tóm tắt bài học
- Retrieval Augmented Generation (RAG) là một công nghệ trong lĩnh vực AI giúp khắc phục hạn chế của các mô hình ngôn ngữ lớn (LLM) như GPT, đặc biệt là trong việc cập nhật thông tin và truy xuất dữ liệu.
- RAG hoạt động bằng cách truy xuất thông tin từ các nguồn bên ngoài và sử dụng thông tin đó làm ngữ cảnh để tạo câu trả lời chính xác hơn cho câu hỏi của người dùng.
- Quy trình cơ bản của RAG bao gồm: chuẩn bị dữ liệu, xử lý câu hỏi, tìm kiếm thông tin liên quan, và tạo câu trả lời.
- RAG mang lại nhiều lợi ích như cập nhật kiến thức, độ chính xác, minh bạch trong việc trích dẫn nguồn, và tiết kiệm chi phí cho việc huấn luyện lại mô hình.
- Công nghệ này được ứng dụng trong nhiều lĩnh vực như trả lời câu hỏi, tóm tắt tài liệu, và hỗ trợ khách hàng.
- RAG đóng vai trò quan trọng trong việc tích hợp LLM vào các hệ thống hiện có, giúp đảm bảo tính chính xác và minh bạch trong thông tin trả lời.
Câu hỏi ôn tập
-
RAG (Retrieval Augmented Generation) giải quyết được những hạn chế gì của các mô hình LLM?
RAG giải quyết 4 hạn chế chính của LLM:
- Cập nhật kiến thức mới mà không cần huấn luyện lại mô hình
- Tăng độ chính xác bằng cách cung cấp thông tin từ nguồn đáng tin cậy
- Đảm bảo tính minh bạch thông qua việc trích dẫn nguồn
- Tiết kiệm chi phí so với việc phải huấn luyện/tinh chỉnh lại mô hình
-
Các bước cơ bản trong một flow RAG là gì?
Flow RAG cơ bản gồm 4 bước chính:
- Chuẩn bị dữ liệu: Chuyển đổi dữ liệu thô thành vector embeddings
- Xử lý câu hỏi: Chuyển câu hỏi người dùng thành vector
- Tìm kiếm thông tin liên quan: So sánh vector câu hỏi với cơ sở dữ liệu
- Tạo câu trả lời: LLM kết hợp câu hỏi và thông tin tìm được để trả lời
-
RAG được ứng dụng trong những lĩnh vực nào?
RAG được ứng dụng trong nhiều lĩnh vực như:
- Trả lời câu hỏi dựa trên tài liệu nội bộ
- Tóm tắt báo cáo, tài liệu tự động
- Xây dựng chatbot tư vấn khách hàng
- Hỗ trợ tra cứu và phân tích tài liệu pháp lý
-
Làm thế nào RAG có thể giúp chatbot tư vấn sản phẩm hoạt động hiệu quả?
RAG giúp chatbot tư vấn sản phẩm bằng cách:
- Truy xuất thông tin sản phẩm liên quan từ cơ sở dữ liệu
- Đưa thông tin này vào prompt của LLM
- LLM kết hợp thông tin sản phẩm với câu hỏi để tạo câu trả lời phù hợp
- Cập nhật thông tin sản phẩm mới mà không cần huấn luyện lại mô hình
-
Vector database đóng vai trò gì trong RAG và có bắt buộc phải dùng không?
Vector database trong RAG:
- Dùng để lưu trữ và tìm kiếm hiệu quả các vector embeddings
- Không bắt buộc phải dùng, có thể thay thế bằng các phương thức khác
- Có thể lấy thông tin từ API bên ngoài hoặc query database theo keyword
- Linh hoạt tùy theo nhu cầu và thiết kế hệ thống