Cùng chạy ChatGPT phiên bản sơ sinh
Ở phần này, bọn mình sẽ ôn lại các kiến thức đã học về LLM, và viết code trực tiếp để hiểu cách nó hoạt động luôn nha.
Mục tiêu của khoá học tập trung vào ứng dụng của Generative AI là dành cho các bạn developer, software engineer hiểu rõ về LLM, và có thể sử dụng nó trong các ứng dụng của mình. Do vậy, bọn mình sẽ không quá đi sâu vào các khía cạnh như toán, xác suất thống kê, AI và machine learning cơ bản, mà sẽ tập trung vào việc sử dụng LLM trong thực tế.
Các bạn có thể tưởng tượng LLM giống như một chiếc hộp đen, hoặc một thư viện/API. Bọn mình sẽ hướng dẫn các bạn cách đưa đầu vào, tinh chỉnh đầu ra cho nó. Còn bên trong hộp nó hoạt động cụ thể ra sao, làm sao để tạo ra nó, thì bọn mình sẽ chỉ giới thiệu những phần liền quan tới ứng dụng thôi nha.
Nhắc lại chút kiến thức về LLM
Cho những bạn nào đã quên, LLM (viết tắt của Large Language Module) là một mô hình ngôn ngữ lớn!
Vậy mô hình ngôn ngữ là gì? Mô hình ngôn ngữ (language model) là một mô hình machine learning dùng để dự đoán từ tiếp theo trong một chuỗi từ đã cho, tương tự như chức năng autocomplete trong bàn phím của bạn vậy.

Tại sao gọi nó là lớn?
Một mô hình machine learning có rất nhiều tham số (parameter). Bạn có thể hiểu mỗi tham số tương đương với một tế bào não vậy. Các mô hình này có tầm vài trăm triệu tham số (GPT2) đến vài trăm tỷ tham số (GPT3.5).
LLM không phải là một khái niệm mới, mà đã tồn tại từ khá lâu (từ những năm 2018). Tuy nhiên, các mô hình ngày xưa khá là... nhỏ, ngu và vô dụng. Tuy nhiên, nhờ sự phát triển của GPU, dữ liệu và các thuật toán, các mô hình ngày nay đã lớn hơn, thông minh hơn rất nhiều.
Tuy vậy, bản chất của nó vẫn chỉ là... dự đoán từ tiếp theo từ một chuối từ có sẵn. Do vậy, chúng ta sẽ cùng viết code để hiểu cách nó hoạt động nhé!
Optional (Học Python cơ bản và cài đặt VSCode)
Các bạn nào chưa dùng Python và chưa cài VSCode thì xem lại 2 video này nhé!
-
Tự học lập trình Python trong 10 phút
-
Hướng dẫn cài đặt VSCode
Cùng viết code sử dụng GPT2 để dự đoán từ tiếp theo
Bọn mình sẽ dùng GPT2, phiên bản sơ sinh từ 2019 của dòng GPT. Đây là một model nho nhỏ cute chỉ tầm 137M parameters (nhỏ hơn GPT-5 khoảng chục nghìn lần), nhưng vẫn có khả năng tạo ra văn bản - rất phù hợp để demo cách Transformer/LLM hoạt động mà không cần máy khỏe.
Các bạn có thể xem hướng dẫn bên dưới để cài Python (cài đi những bài sau sẽ cần nha!). Hoặc bấm vào link dưới để mở collab và chạy code ngay trên trình duyệt nhé!
Nếu trước giờ các bạn chưa dùng Google Colab bao giờ thì kéo xuống dưới xem hướng dẫn nhé, cũng không khó lắm đâu!
![]()
Nếu các bạn chưa dùng Python bao giờ thì cũng đừng ngại. Cấu trúc code của Python rất dễ hiểu, đọc như đọc Pseudocode vậy á!
Việc chạy code rất đơn giản. Nếu trên Mac thì bạn đã có Python sẵn rồi, còn Windows thì bạn phải cài nha!
1. Cài đặt Python cho Windows
Bạn nên dùng Python 3.11 hoặc 3.12 (ổn định nhất với các thư viện AI hiện nay). Python 3.13 cũng đã hỗ trợ hầu hết thư viện nhưng một số còn lỗi lẻ tẻ. Tải từ trang chủ Python.
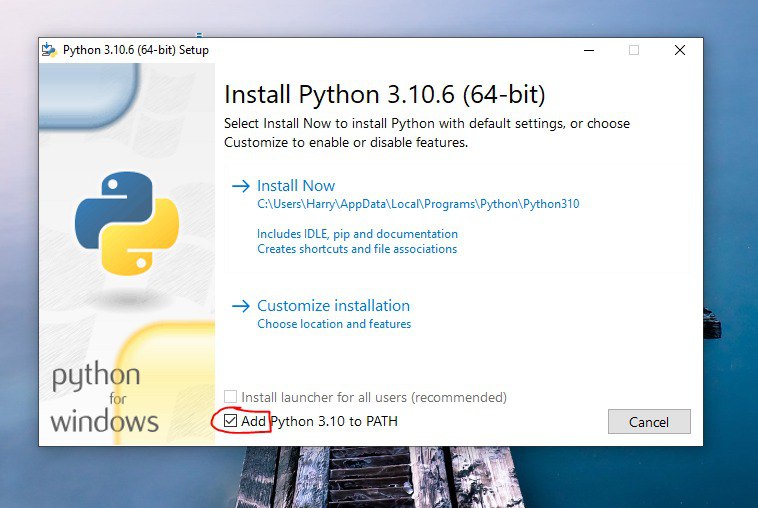
Các bạn nhớ tick
Add Python to PATHnha!
Sau khi cài xong, ta kiểm tra lại bằng cách:
-
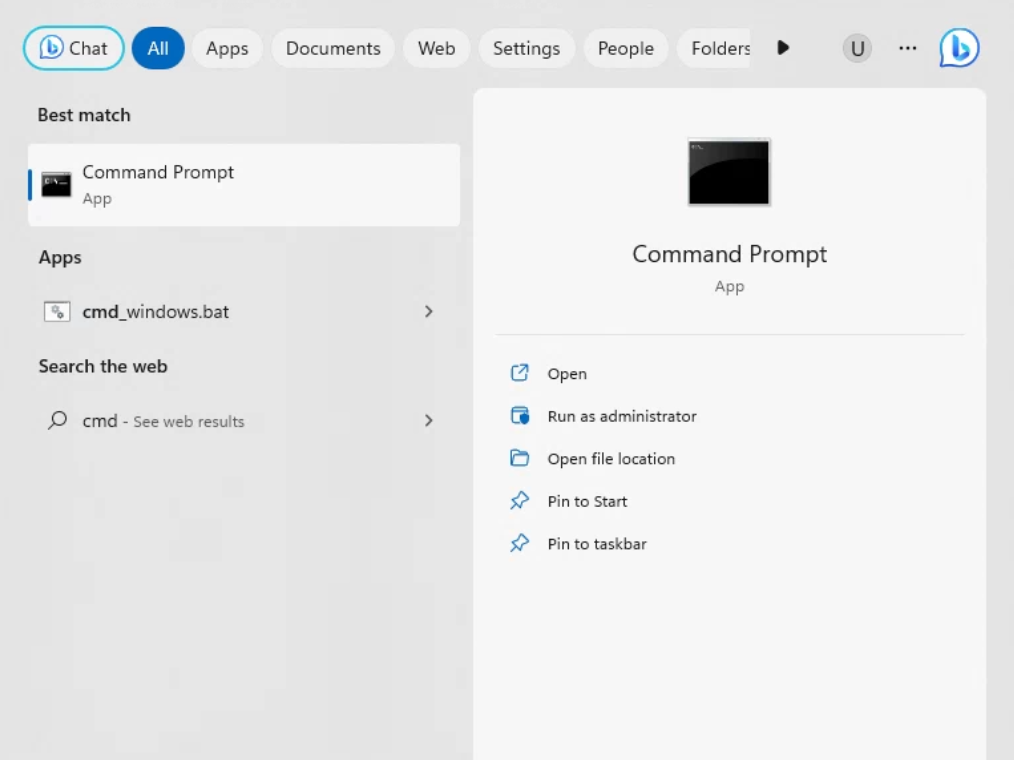
Nhấn phím Windows trên bàn phím và gõ "cmd" để tìm một chương trình có tên "Command Prompt".
-
Mở ứng dụng Command Prompt.
-
Bạn sẽ thấy một terminal đen thui như hacker
-
Gõ "python" và nhấn Enter. Thấy in ra Python 3.11/3.12 là được.
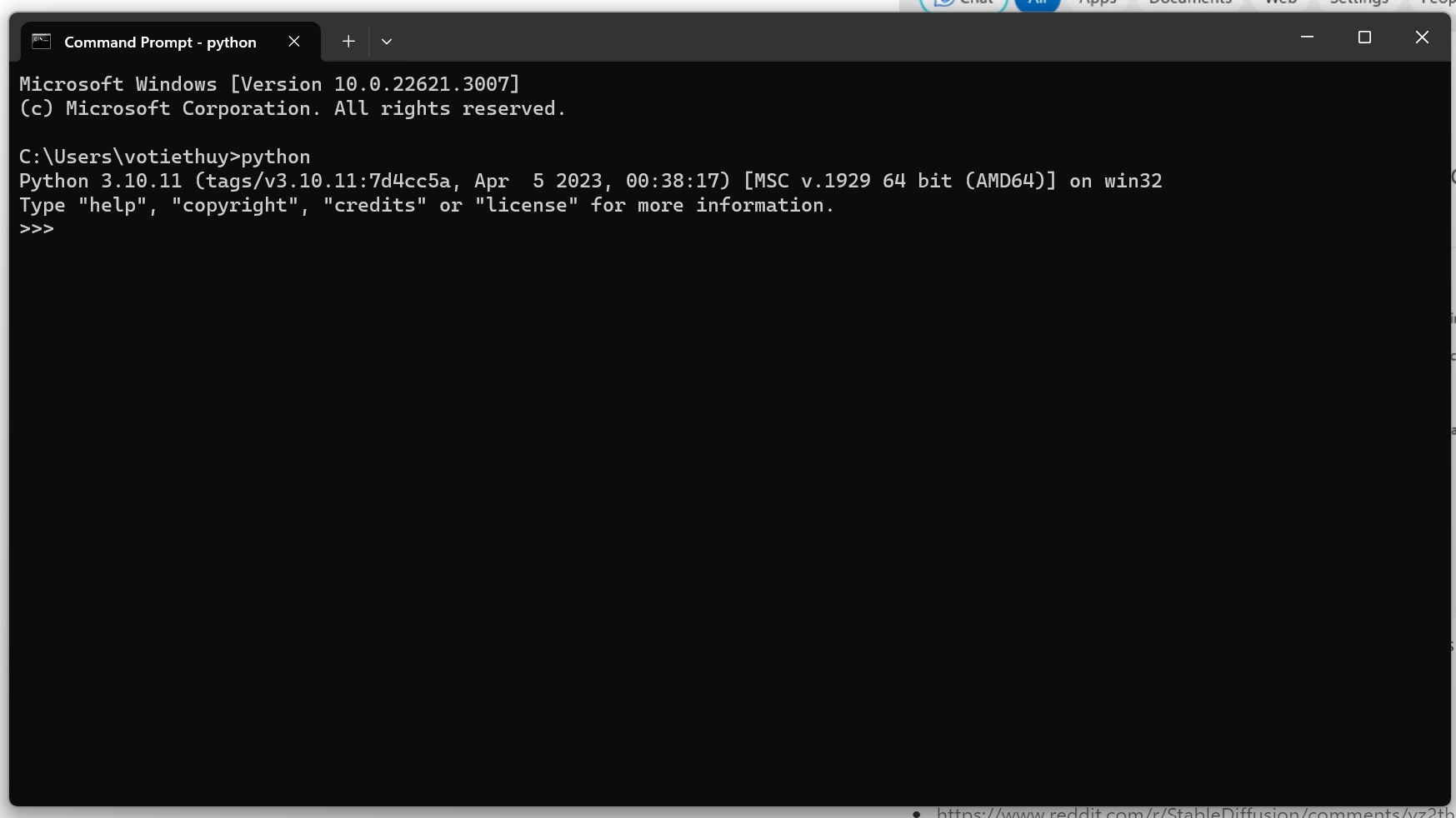
Nếu bạn không thấy Python chạy, bạn có thể thử:
- Khởi động lại PC
- Installer hoặc cài lại trên trang web Python.
2: Cài đặt thư viện transformers
Đầu tiên chúng ta sẽ cài thư viện transformers. Đây là thư viện mà Huggingface đã viết ra để giúp chúng ta sử dụng các mô hình ngôn ngữ một cách dễ dàng hơn.
Các bạn mở Command Prompt trên Windows, hoặc Terminal trên Mac (Sử dụng phím tắt Command + và gõ Terminal)
Ta gõ dòng lệnh sau để cài thư viện transformers:
pip install torch
pip install transformers
Ở những bài sau cũng vậy. Khi dùng pip install, các bạn nhớ mở command prompt lên để dùng pip nha.
3. Viết code
Sau đó, các bạn dán dòng code này vào 1 file gpt.py và chạy bằng lệnh python 01-gpt.py. (Các bạn nào dùng Colab thì cứ bấm vào từng cell code nhé!)
# Import các thư viện cần thiết
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load model và tokenizer (tokenizer là gì mình sẽ giải thích ở bài sau nhé)
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
# Tạo input cho model, chuẩn bị cho việc dự đoán
model_inputs = tokenizer('I enjoy walking with my cute dog', return_tensors='pt')
# Dự đoán 40 token tiếp theo
greedy_output = model.generate(**model_inputs, max_new_tokens=40)
# In kết quả ra
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))
Bạn sẽ thấy kết quả in ra dưới console, GPT2 đã dự đoán 40 từ tiếp theo từ câu I enjoy walking with my cute dog.
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with my dog. I'm not sure if I'll ever be able to walk with my dog.
I'm not sure
OK, chúc mừng bạn. Bạn đã hoàn thành đoạn code đầu tiên sử dụng GPT2 rồi đó!
Về cơ bản, ChatGPT (GPT-5) cũng hoạt động tương tự vậy: đưa câu hỏi vào input, output sẽ là câu trả lời, bản chất là dự đoán token tiếp theo. Có điều mô hình GPT-5 / Claude Opus 4.7 / Gemini 3 Pro phía sau lớn hơn GPT2 hàng chục nghìn lần, được training trên dữ liệu lớn hơn rất nhiều và có thêm các giai đoạn RLHF, reasoning training, multimodal training…
Ở bài sau, mình sẽ giải thích thêm về cách mà transformer sinh ra văn bản, cũng như các paramters/tham số mà các bạn cần biết nha!
Bonus - Cách dùng Google Collab
Đây là giao diện các bạn sẽ thấy khi mới mở Colab.
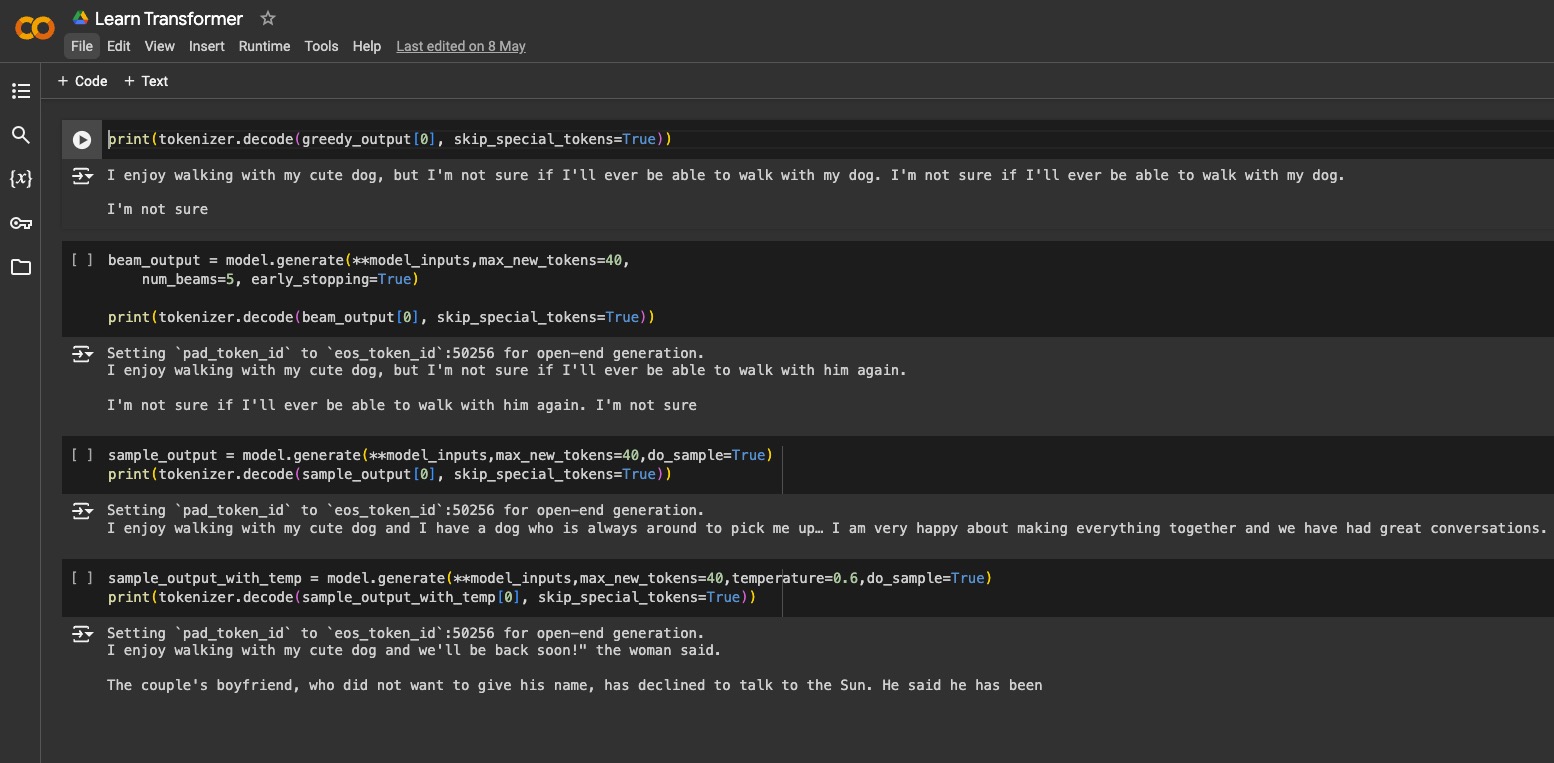
Để chạy code, các bạn kéo lên trên cùng và bấm nút Play ở góc trên bên trái là được, sau đó bấm Run anyway.
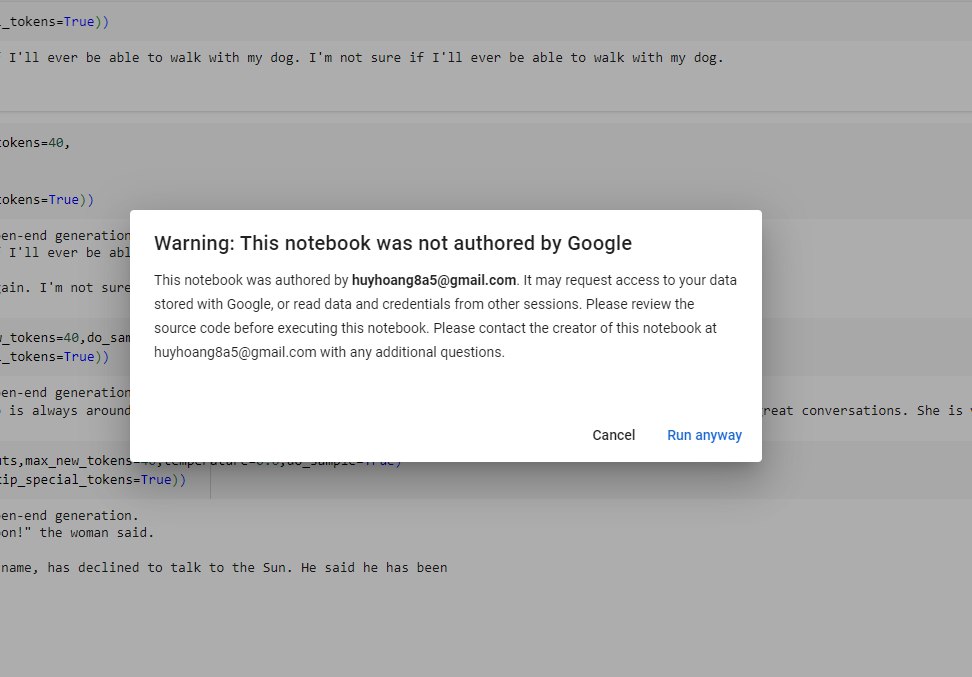
Mặc định, Google Collab sẽ sử dụng CPU. Ở những bài sau, chúng ta sẽ cần GPU để chạy mô hình lớn hơn, các bạn bấm vào Runtime -> Change runtime type -> GPU nhé!
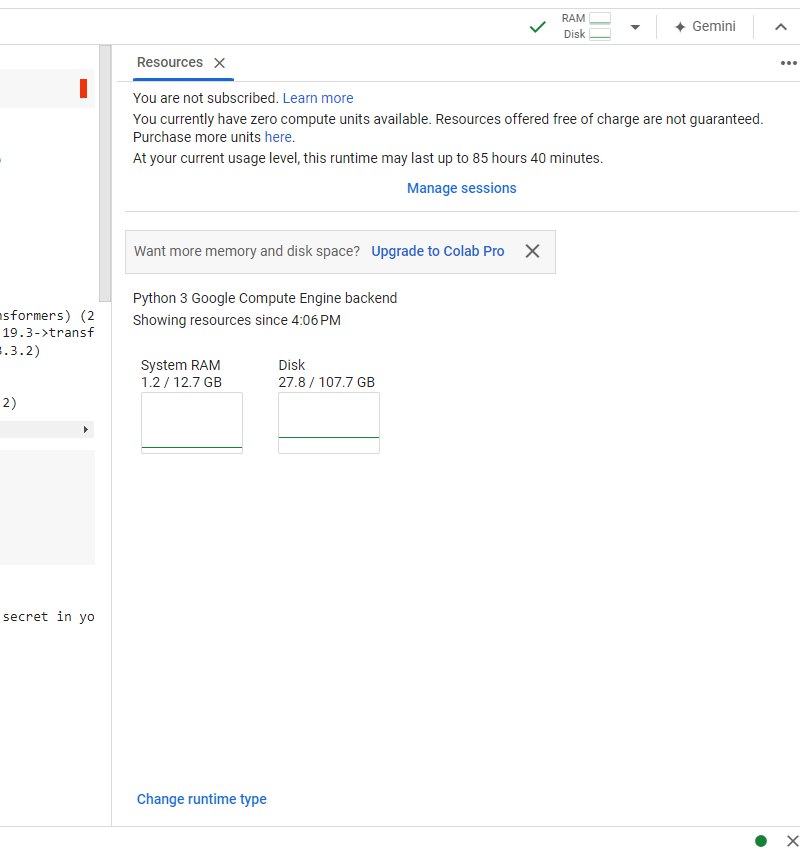
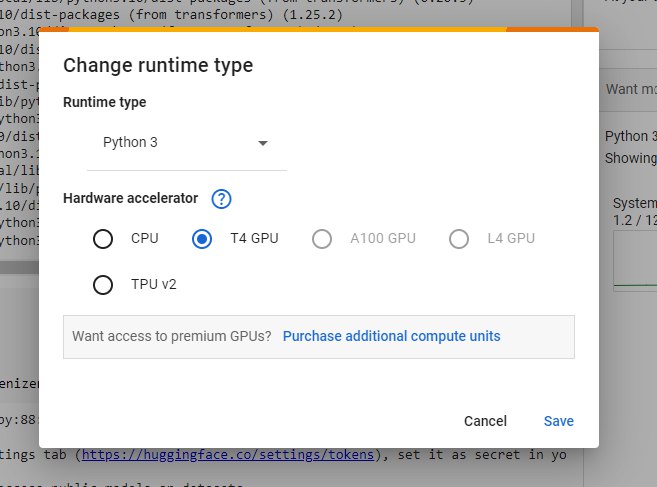
Với gói free, trong 1 ngày các bạn sẽ được sử dụng GPU trong một giới hạn. Nếu bạn cần sử dụng nhiều hơn, các bạn có thể nâng cấp lên gói Pro, tầm 10$ là đủ dùng cho các bài sau và mục Stable Diffusion rồi nhé!
Bonus - uv - công cụ quản lý Python hiện đại (khuyến nghị 2026)
Nếu bạn mới bắt đầu, mình khuyến nghị dùng uv - công cụ Python package manager viết bằng Rust, nhanh hơn pip 10-100 lần, quản lý luôn cả Python version. Từ 2025-2026 uv đã trở thành chuẩn mới trong cộng đồng Python/AI.
# macOS/Linux
curl -LsSf https://astral.sh/uv/install.sh | sh
# Windows (PowerShell)
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
Dùng uv rất đơn giản:
# Tạo project mới, tự install Python 3.12
uv init myproject
cd myproject
# Thêm package (tự tạo venv, tự cài)
uv add torch transformers
# Chạy file Python trong venv của project
uv run gpt.py
Còn nếu bạn thích cách cũ (pyenv + virtualenv) thì đọc tiếp phía dưới nha.
Pyenv + Virtualenv (cách truyền thống)
Bạn đã bao giờ gặp tình huống này chưa: một dự án cần Python 2.7, dự án khác lại yêu cầu Python 3.8, và dự án mới nhất đòi hỏi Python 3.10? Đừng lo, chúng ta có Pyenv - trợ thủ đắc lực để giải quyết vấn đề này!
Pyenv là gì?
Pyenv giống như một "người quản lý" giúp bạn:
- Cài đặt nhiều phiên bản Python khác nhau
- Chuyển đổi giữa các phiên bản Python dễ dàng như trở bàn tay
- Đảm bảo mỗi dự án đều chạy đúng phiên bản Python mà nó cần
Virtualenv là gì?
Virtualenv là một "phòng thí nghiệm ảo" cho Python. Nó giúp bạn:
- Tạo môi trường riêng biệt cho từng dự án
- Cài đặt các thư viện mà không sợ xung đột
- Dễ dàng chia sẻ dự án với người khác mà không lo về sự khác biệt môi trường
Hướng dẫn cài đặt chi tiết
Đối với máy Mac hoặc Linux:
Cách 1: Sử dụng Homebrew (Khuyến nghị cho Mac)
brew install pyenv
Cách 2: Cài đặt tự động
curl https://pyenv.run | bash
Bước tiếp theo: Cấu hình môi trường
Nếu bạn dùng bash (kiểm tra bằng cách gõ echo $SHELL):
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc
echo 'command -v pyenv >/dev/null || export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc
echo 'eval "$(pyenv init -)"' >> ~/.bashrc
Nếu bạn dùng zsh:
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.zshrc
echo '[[ -d $PYENV_ROOT/bin ]] && export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.zshrc
echo 'eval "$(pyenv init -)"' >> ~/.zshrc
Cài đặt thêm Virtualenv:
brew install pyenv-virtualenv
Sau đó thêm dòng này vào file cấu hình (~/.zshrc hoặc ~/.bashrc):
eval "$(pyenv virtualenv-init -)"
Đối với Windows:
Windows có phiên bản riêng gọi là pyenv-win. Các bước cài đặt như sau:
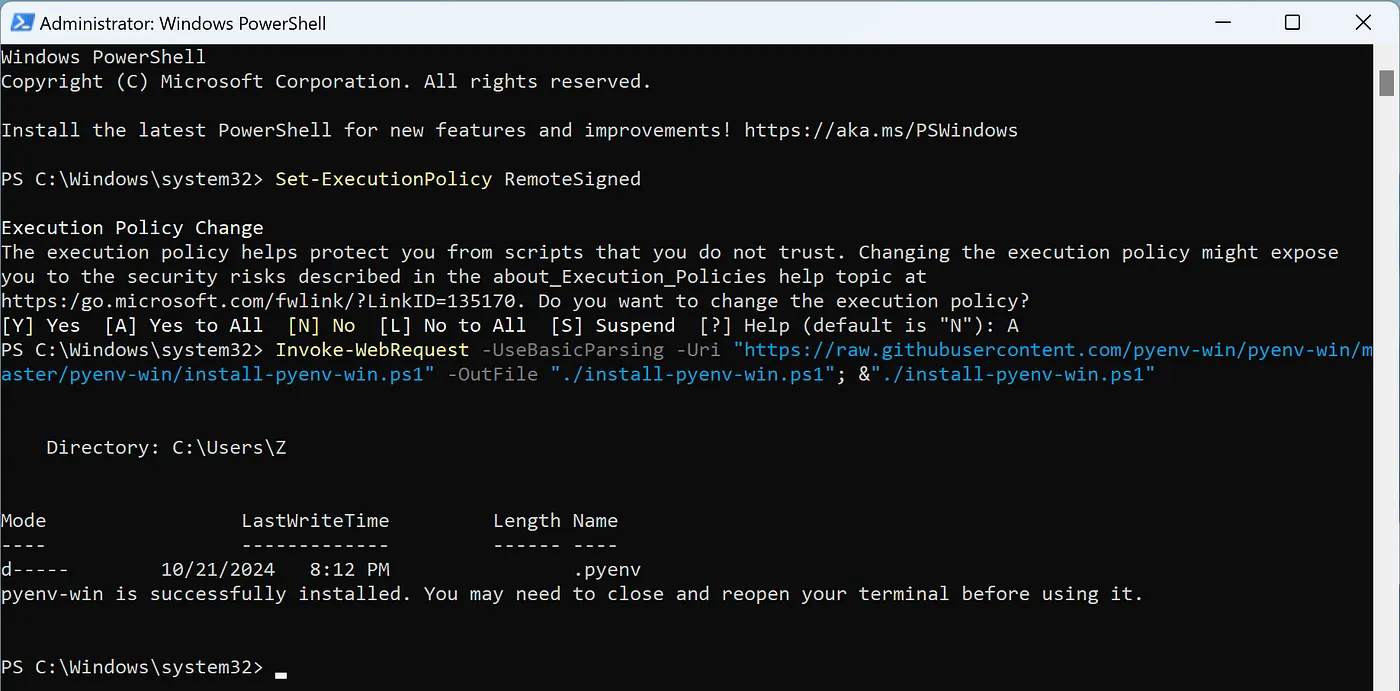
- Mở PowerShell với quyền Administrator và chạy:
Invoke-WebRequest -UseBasicParsing -Uri "https://raw.githubusercontent.com/pyenv-win/pyenv-win/master/pyenv-win/install-pyenv-win.ps1" -OutFile "./install-pyenv-win.ps1"; &"./install-pyenv-win.ps1"
-
Khởi động lại PowerShell
-
Kiểm tra cài đặt:
- Gõ
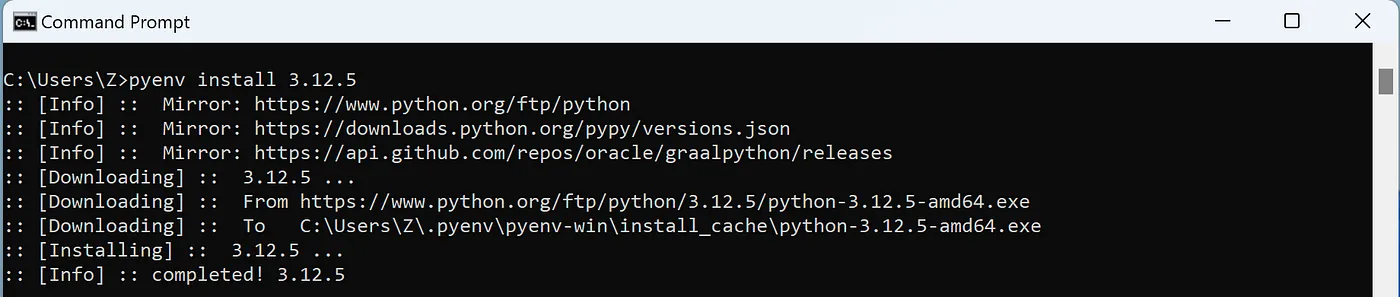
pyenv --version- nếu hiện phiên bản là đã thành công - Gõ
pyenv install -lđể xem danh sách Python có thể cài - Cài Python bằng lệnh
pyenv install 3.12.7(hoặc phiên bản bạn muốn)
- Cài thêm công cụ tạo môi trường ảo:
Invoke-WebRequest -UseBasicParsing -Uri "https://raw.githubusercontent.com/pyenv-win/pyenv-win-venv/main/bin/install-pyenv-win-venv.ps1" -OutFile "$HOME\install-pyenv-win-venv.ps1";
&"$HOME\install-pyenv-win-venv.ps1"
Cách sử dụng cơ bản
1. Quản lý phiên bản Python
# Cài đặt Python mới
pyenv install 3.12.7
# Đặt Python mặc định cho toàn máy
pyenv global 3.12.7
# Đặt Python cho thư mục hiện tại
pyenv local 3.12.7
# Xem các lệnh hữu ích khác
pyenv help
2. Làm việc với môi trường ảo
Trên Mac/Linux:
# Tạo môi trường ảo mới
pyenv virtualenv tên_môi_trường
# Kích hoạt môi trường
pyenv activate tên_môi_trường
# Tắt môi trường
pyenv deactivate
Trên Windows:
# Tạo môi trường ảo
pyenv-venv install 3.12.7 tên_môi_trường
# Kích hoạt môi trường
pyenv-venv activate tên_môi_trường
# Tắt môi trường
pyenv-venv deactivate
💡 Mẹo hay:
- Luôn tạo môi trường ảo mới cho mỗi dự án
- Đặt tên môi trường ảo liên quan đến dự án để dễ nhớ
- Sử dụng
pyenv localđể tự động kích hoạt đúng phiên bản Python khi vào thư mục dự án
Tài liệu đọc thêm
- https://jalammar.github.io/illustrated-gpt2
- https://huggingface.co/blog/how-to-generate
- https://huggingface.co/docs/transformers/main/en/llm_tutorial
- https://github.com/pyenv/pyenv
- https://github.com/pyenv/pyenv-virtualenv
- https://github.com/pyenv-win/pyenv-win/wiki
- https://github.com/pyenv-win/pyenv-win-venv
⭐ Source code (cho khoá Engineer): 01-text-generation/01-gpt.py
Tóm tắt bài học
- Trong phần này, ta ôn lại kiến thức về LLM (Large Language Model) và viết code trực tiếp để hiểu cách hoạt động của nó.
- Mục tiêu của khóa học là giúp developer và software engineer hiểu rõ về Generative AI và ứng dụng của LLM mà không đi sâu vào các khía cạnh toán học hay machine learning cơ bản.
- LLM được coi như một hộp đen hoặc một thư viện/API, nơi chúng ta sẽ học cách đưa đầu vào và tinh chỉnh đầu ra mà không cần tìm hiểu chi tiết bên trong.
- Mô hình ngôn ngữ dự đoán từ tiếp theo trong chuỗi từ đã cho, với các mô hình hiện nay có từ vài trăm triệu đến hàng trăm tỷ tham số.
- Hướng dẫn viết code sử dụng GPT2, phiên bản nhỏ hơn của GPT3, để dự đoán từ tiếp theo, và cung cấp hướng dẫn cài đặt Python và VSCode.
- Cuối cùng, chia sẻ cách sử dụng Google Colab để chạy code, bao gồm việc thay đổi kiểu runtime sang GPU cho các mô hình lớn hơn trong tương lai.
Câu hỏi ôn tập
-
Tại sao LLM ngày nay lại phát triển mạnh hơn so với những năm 2018 mặc dù khái niệm không mới?
Do 3 yếu tố chính: sự phát triển của GPU giúp tăng khả năng tính toán, lượng dữ liệu training lớn hơn, và các thuật toán được cải tiến. Những yếu tố này giúp các mô hình ngày nay có thể xử lý nhiều tham số hơn (từ vài trăm triệu đến vài trăm tỷ parameters), dẫn đến khả năng thông minh và hiệu quả cao hơn nhiều so với trước đây.
-
Làm thế nào để chạy được mô hình GPT-2 cơ bản trên máy tính cá nhân?
Để chạy GPT-2, bạn cần: (1) Cài đặt Python, (2) Cài thư viện transformers thông qua pip install transformers, (3) Viết code sử dụng AutoModelForCausalLM và AutoTokenizer từ transformers để load model và tokenizer, (4) Tạo input và generate text. Hoặc đơn giản hơn có thể sử dụng Google Colab để chạy trực tiếp trên trình duyệt.
-
Sự khác biệt chính giữa GPT-2 và GPT-3.5 là gì?
GPT-2 chỉ có khoảng 137M parameters (tham số), trong khi GPT-3.5 lớn hơn khoảng 1000 lần. Điều này làm cho GPT-3.5 có khả năng xử lý ngôn ngữ phức tạp hơn và cho kết quả chính xác, thông minh hơn nhiều so với GPT-2.
-
Khi sử dụng Google Colab miễn phí để chạy các mô hình AI, có những giới hạn gì cần lưu ý?
Khi sử dụng Google Colab phiên bản miễn phí, người dùng sẽ bị giới hạn thời gian sử dụng GPU trong một ngày. Nếu cần sử dụng nhiều hơn, có thể nâng cấp lên gói Pro với chi phí khoảng 10$ để có nhiều tài nguyên hơn cho việc chạy các mô hình AI.